Naive VQA: Implementations of a Strong VQA Baseline
Published:
What’s VQA?
Visual Qustion Answering (VQA) is a type of tasks, where given an image and a question about the image, a model is expected to give a correct answer.
For example, a visual image looks like this:

The question is: What color is the girl’s necklace?
Our model would generate the answer ‘white’.
What’s MindSpore?
MindSpore is a new AI framework developed by Huawei.
NaiveVQA: MindSpore & PyTorch Implementations of a Strong VQA Baseline
This repository contains a naive VQA model, which is our final project (mindspore implementation) for course DL4NLP at ZJU. It’s a reimplementation of the paper Show, Ask, Attend, and Answer: A Strong Baseline For Visual Question Answering.
Checkout branch
pytorchfor our pytorch implementation.
git checkout pytorch
Performance
| Framework | Y/N | Num | Other | All |
|---|---|---|---|---|
| MindSpore | 62.2 | 7.5 | 2.4 | 25.8 |
| PyTorch | 66.3 | 24.5 | 25.0 | 40.6 |
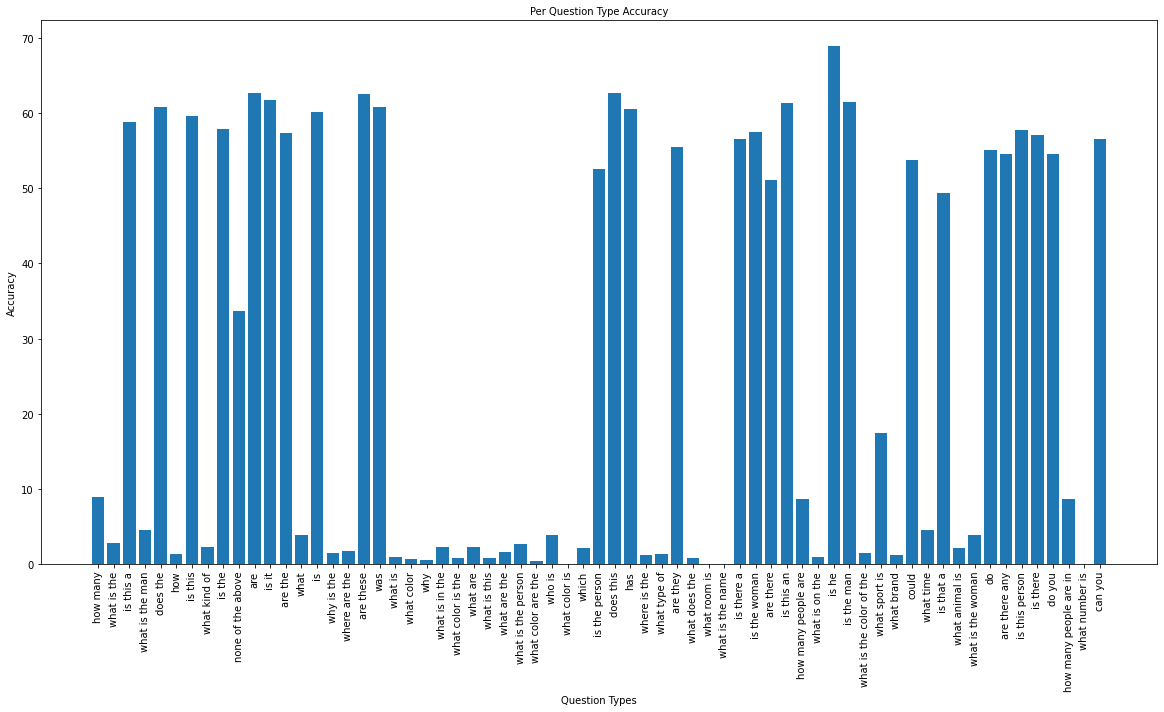
Per Question Type Accuracy (MindSpore)
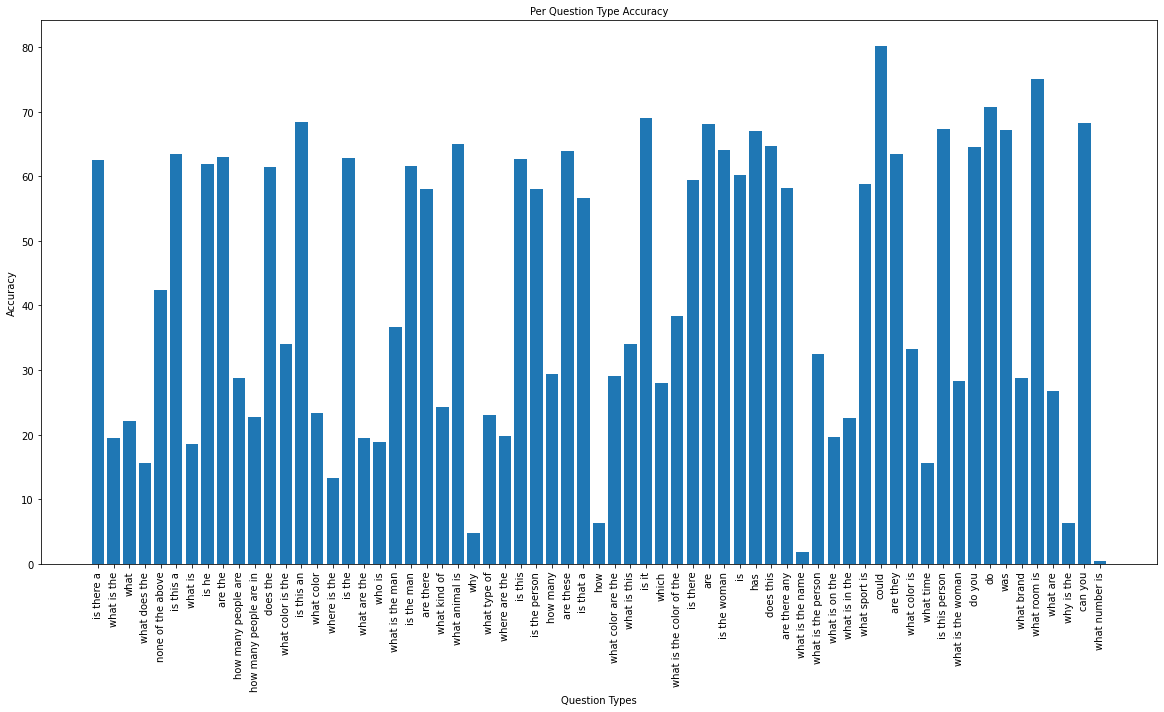
Per Question Type Accuracy (PyTorch)
File Directory
data/annotations/– annotations data (ignored)images/– images data (ignored)questions/– questions data (ignored)results/– contains evaluation results when you evaluate a model with./evaluate.ipynbclean.py– a script to clean uptrain.jsonin bothdata/annotations/anddata/questions/align.py– a script to sort and align up the annotations and questions
resnet/– resnet directory, cloned from pytorch-resnetlogs/– should contain saved.pthmodel filesconfig.py– global configure filetrain.py– trainingview-log.py– a tool for visualizing an accuracy\epoch figureval_acc.png– a demo for the accuracy\epoch figuremodel.py– the major modelpreprocess-image.py– preprocess the images, using ResNet152 to extract features for further usagespreprocess-image-test.py– to extract images in the test setpreprocess-vocab.py– preprocess the questions and annotations to get their vocabularies for further usagesdata.py– dataset, dataloader and data processing codeutils.py– helper codeevaluate.ipynb– evaluate a model and visualize the resultcover_rate.ipynb– calculate the selected answers’ coverageassets/PythonHelperTools/(currently not used)vqaDemo.py– a demo for VQA dataset APIsvqaTools/
PythonEvaluationTools/(currently not used)vqaEvalDemo.py– a demo for VQA evaluationvaqEvaluation/
README.md
Prerequisite
- Free disk space of at least 60GB
- Nvidia GPU / Ascend Platform
Notice: We have successfully tested our code with MindSpore 1.2.1 on Nvidia RTX 2080ti. Thus we strongly suggest you use MindSpore 1.2.1 GPU version. Since MindSpore is definitely not stable, any version different from 1.2.1 might cause failures.
Also, due to some incompatibility among different versions of MindSpore, we still can’t manage to run the code on Ascend now. Fortunately, people are more possible to have an Nvidia GPU rather than an Ascend chip :)
Quick Begin
Get and Prepare the Dataset
Get our VQA dataset (a small subset of VQA 2.0) from here. Unzip the file and move the subdirectories
annotations/images/questions/
into the repository directory data/.
Prepare your dataset with:
# Only run the following command once!
cd data
# Save the original json files
cp annotations/train.json annotations/train_backup.json
cp questions/train.json questions/train_backup.json
cp annotations/val.json annotations/val_backup.json
cp questions/val.json questions/val_backup.json
cp annotations/test.json annotations/test_backup.json
cp questions/test.json questions/test_backup.json
python clean.py # run the clean up script
mv annotations/train_cleaned.json annotations/train.json
mv questions/train_cleaned.json questions/train.json
python align.py # run the aligning script
mv annotations/train_cleaned.json annotations/train.json
mv annotations/val_cleaned.json annotations/val.json
mv annotations/test_cleaned.json annotations/test.json
mv questions/train_cleaned.json questions/train.json
mv questions/val_cleaned.json questions/val.json
mv questions/test_cleaned.json questions/test.json
The scripts upon would
- clean up your dataset (there are some images whose ids are referenced in the annotation & question files, while the images themselves don’t exist!)
- align the questions’ ids for convenience while training
Preprocess Images
You actually don’t have to preprocess the images yourself. We have prepared the prerocessed features file for you, feel free to download it through here (the passcode is ‘dl4nlp’). You should download the
resnet-14x14.h5(42GB) file and place it at the repository root directory. Once you’ve done that, skip this chapter!
Preprocess the images with:
python preprocess-images.py
- If you want to accelerate it, tune up
preprocess_batch_sizeatconfig.json - If you run out of CUDA memory, tune down
preprocess_batch_sizeataconfig.json
The output should be ./resnet-14x14.h5.
Preprocess Vocabulary
The vocabulary only depends on the train set, as well as the
config.max_answers(the number of selected candidate answers) you choose.
Preprocess the questions and annotations to get their vocabularies with:
python preprocess-vocab.py
The output should be ./vocab.json.
Train
Now, you can train the model with:
python train.py
During training, a ‘.ckpt’ file and a ‘.json’ file would be saved under ./logs. The .ckpt file contains the parameters of your model and can be reloaded. The .json file contains training metainfo records.
View the training process with:
python view-log.py <path to .json train record>
The output val_acc.png should look like these:
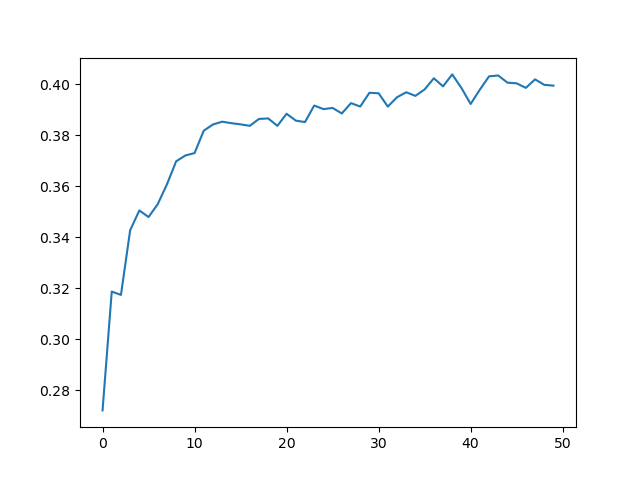
(a real train of PyTorch implementation)
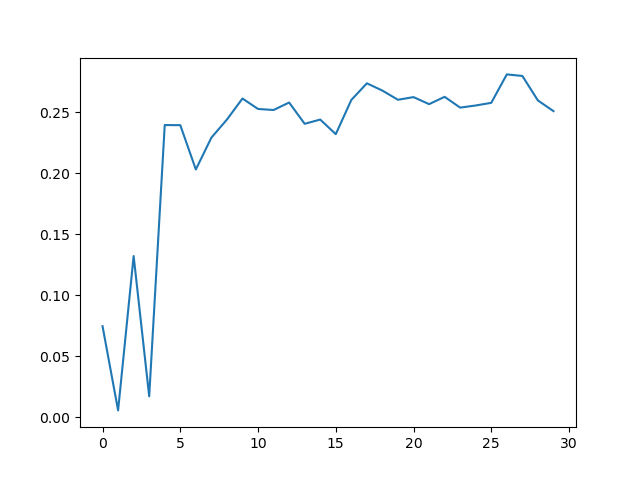
(a real train of MindSpore implementation)
To continue training from a pretrained model, set the correct
pretrained_model_pathand thepretrainedto True inconfig.py.
Test Your Model
Likewise, you need to preprocess the test set’s images before testing. Run
python preprocess-images-test.py
to extract features from test/images. The output should be ./resnet-14x14-test.h5.
Likewise, we have prepared the
resnet-14x14-test.h5for you. Download it here (the passcode is ‘dl4nlp’)
We provide evaluatie.ipynb to test/evaluate the model. Open the notebook, and set the correct eval_config, you’re good to go! Just run the following cell one by one, you should be able to visualize the performance of your trained model.
More Things
- To calculate the selected answers’ cover rate (determined by
config.max_answers), checkcover_rate.ipynb.
Acknowledgement
The current version of codes are translated from pytorch branch, where some codes are borrowed from repository pytorch-vqa.