
Revisiting the Assumption of Latent Separability for Backdoor Defenses
[pdf] ICLR 2023, 2023
Our code is publicly available at https://github.com/Unispac/Circumventing-Backdoor-Defenses.
Recent studies revealed that deep learning is susceptible to backdoor poisoning attacks. An adversary can embed a hidden backdoor into a model to manipulate its predictions by only modifying a few training data, without controlling the training process. Currently, a tangible signature has been widely observed across a diverse set of backdoor poisoning attacks — models trained on a poisoned dataset tend to learn separable latent representations for poison and clean samples. This latent separation is so pervasive that a family of backdoor defenses directly take it as a default assumption (dubbed latent separability assumption), based on which to identify poison samples via cluster analysis in the latent space.
An intriguing question consequently follows: is the latent separation unavoidable for backdoor poisoning attacks? This question is central to understanding whether the assumption of latent separability provides a reliable foundation for defending against backdoor poisoning attacks. In this paper, we design adaptive backdoor poisoning attacks to present counter-examples against this assumption.
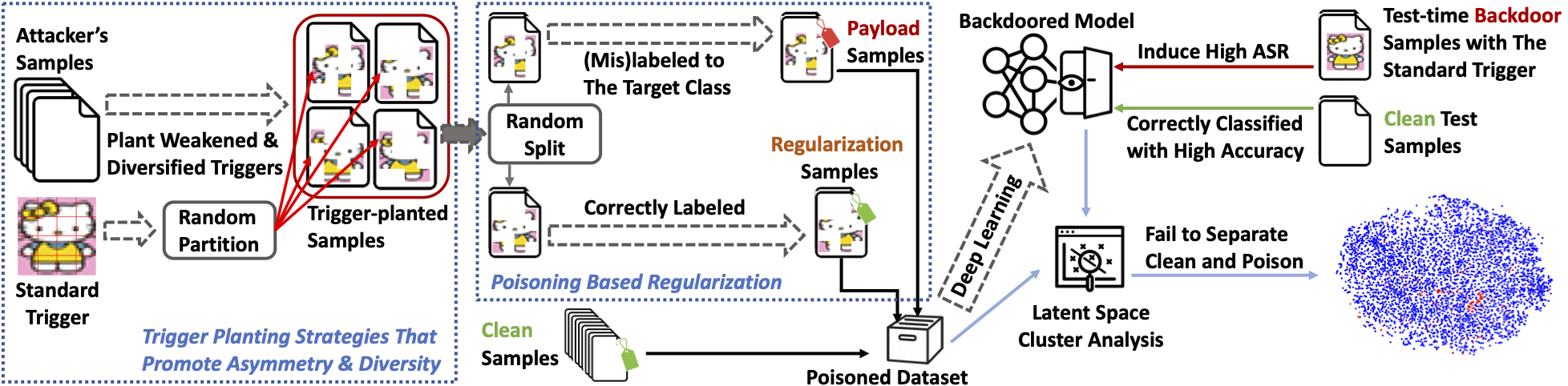
Our methods include two key components: (1) a set of trigger-planted samples correctly labeled to their semantic classes (other than the target class) that can regularize backdoor learning; (2) asymmetric trigger planting strategies that help to boost attack success rate (ASR) as well as to diversify latent representations of poison samples.
Extensive experiments on benchmark datasets verify the effectiveness of our adaptive attacks in bypassing existing latent separation based backdoor defenses. Moreover, our attacks still maintain a high attack success rate with negligible clean accuracy drop. Our studies call for defense designers to take caution when leveraging latent separation as an assumption in their defenses.